
“Bob: So, how do I query the database? IT guy: It’s not a database. It’s a Key-Value store. . . . You write a distributed map-reduce function in Erlang. Bob: Did you just tell me to go **** myself? IT guy: I believe I did, Bob.”
—Fault Tolerance cartoon, @jrecursive, 2009
Prelude
Relational databases have been around for a while now. It was necessitated with the emergence of web technologies. From its advance in 1995 to its cusp in 2005, it remained a stable and more or less the center piece of the web the revolution. But behind the scenes things were churning, especially with the arrival of web 2.0 and and the need of massive processing capability for big data. This was the age of Amazon, the largest retail operator of the time, arguably with a huge web presence. While web 1.0 was a collection of statically linked pages, web 2.0 was all about dynamic content and its necessity to search and index these pages with transnational capabilities
Amazon, in it’s early days used Common Gateway Interface (CGI) to facilitate user interaction. CGI allowed an HTTP request to invoke a script rather than display a HTML page. Scripts written in pearl were used to access the database and generate pages on the fly. As technology progressed CGI gave way to frameworks such as Java’s J2EE and ASP.NET along with PHP (that followed the CGI model). Despite these advances the basic pattern for for data access, retrieval and rendering of dynamic pages remained unchanged.
At this juncture, scaling was not a big issue, a bottle neck in the client /server or web/server layer could as easily be fixed by piling on more internet servers to meet the rising demands in traffic. However fixing a bottleneck at the database layer was not so simple. Like the web / server fix, in the early days , these issues were fixed by upgrading to the latest and greatest hardware, operating systems and databases and what have you.
With the crash of the internet bubble, two realities came into play
- Indefinite expenses in scaling up to the latest and greatest was no longer viable and economical
- Startups, came into being and they needed a more realistic solution, one that involved scaling up from a pint sized infrastructure to the potential of meeting a a global market as the companies grew.
The Open-source Solution
Following the dot.com crash, open-source software became increasingly valued within Web 2.0 operations. Linux supplanted proprietary UNIX as the operating system of choice, and the Apache web server became dominant. During this period, MySQL overtook Oracle as the Database Management System (DBMS) of choice for website development.
MySQL is less scalable than Oracle & generally runs on less powerful hardware and is not very good at taking advantage of multi-core processors, but the development community came up with some nifty tricks to enhance the value of MySQL .
- A technology called Memcached was developed to prevent database access as much as possible. Memcached is an open-source utility that provides a distributed object cache. This allowed for Object-oriented languages to cache objects whose information spanned across multiple tables as objects in memory that could be stored and accessed across multiple servers. By reading from these servers rather than the database, the load on the database could be reduced.
- Web developers took advantage of MySQL replication. Replication allows changes to one database to be copied to another database. Read requests could be directed to any one of these replica databases. Write operations still had to go to the master database however, because master-to-master replication was not possible. However, in a typical database application—and particularly in web applications—reads significantly outnumber writes, so the read replication strategy made sense.
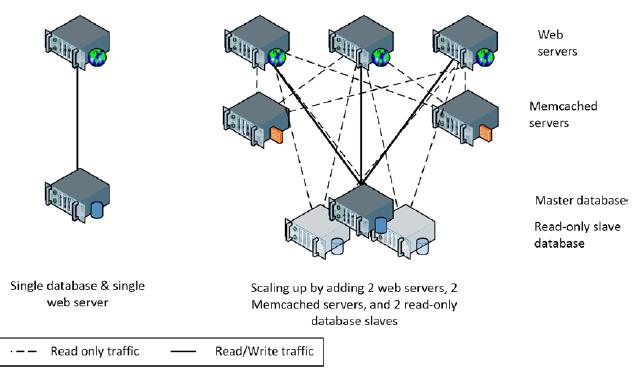
Figure 1 illustrates the transition from single web server and database server to multiple web servers, Memcached servers, and read-only database replicas.
Memcached and read replication increased the overall capacity of MySQL-based web applications dramatically. While the read capabilities of a system can be improved using these methods, database write activities required a more dramatic solution.
Sharding
Sharding allows a logical database to be partitioned across multiple physical servers.
In a sharded application, the largest tables are partitioned across multiple database servers. Each partition is referred to as a shard. This partitioning is based on a Key Value, such as a user ID. When operating on a particular record, the application must determine which shard will contain the data and then send the SQL to the appropriate server. Sharding is a solution used in large scale applications like Twitter and Facebook.

In this example, there are three shards, and for simplicity’s sake, the shards are labeled by first letter of the primary key. As a result, we might imagine that rows with the key GUY are in shard 2, while key BOB would be allocated to shard 1. In practice, it is more likely that the primary key would be hashed to ensure even distribution of keys to servers.
Sharding involves significant operational complexities and compromises, but it is a proven technique for achieving data processing on a massive scale. Sharding is simple in concept but incredibly complex in practice. The application must contain logic that understands the location of any particular piece of data and the logic to route requests to the correct shard. Sharding is usually associated with rapid growth, so this routing needs to be dynamic. Requests that can only be satisfied by accessing more than one shard thus need complex coding as well, whereas on a nonsharded database a single SQL statement might suffice.
Death by a Thousand Shards
Sharding—together with caching and replication—is arguably the only way to scale a relational database to massive web use. However, the operational costs of sharding are huge. Among the drawbacks of a sharding strategy are:
- Application complexity. It’s up to the application code to route SQL requests to the correct shard. In a statically sharded database, this would be hard enough; however, most massive websites are adding shards as they grow, which means that a dynamic routing layer must be implemented. This layer is often in addition to complex code being required to maintain Memcached object copies and to differentiate between the master database and read-only replicas.
- Crippled SQL. In a sharded database, it is not possible to issue a SQL statement that operates across shards. This usually means that SQL statements are limited to rowlevel access. Joins across shards cannot be implemented, nor can aggregate GROUP BY operations. This means, in effect, that only programmers can query the database as a whole.
- Loss of transactional integrity. ACID transactions against multiple shards are not possible—or at least not practical. It is possible in theory to implement transactions across databases in some database systems—those supporting Two Phase Commit (2PC)—but in practice this creates problems for conflict resolution, can create bottlenecks, has issues for MySQL, and is rarely implemented.
- Operational complexity. Load balancing across shards becomes extremely problematic. Adding new shards requires a complex re-balancing of data. Changing the database schema also requires a rolling operation across all the shards, resulting in transitory inconsistencies in the schema. In short, a sharded database entails a huge amount of operational effort and administrator skill.
Source : Guy Harrison ; Next Generation Databases.

I enjoyed reading this. Thanks for the follow over at my blog. Love yours, God & Code. Interesting.
LikeLiked by 3 people
thanks
LikeLiked by 3 people
great post!
LikeLiked by 1 person
[…] via Shard or be Shredded — Life Less Ordinary […]
<! —
PDRTJS_settings_8450511_comm_2127={“id”:8450511,”unique_id”:”wp-comment-2127″,”title”:”%26%23091%3B%26%238230%3B%26%23093%3B%20via%20Shard%20or%20be%20Shredded%20%20Life%20Less%20Ordinary%20%26%23091%3B%26%238230%3B%26%23093%3B&;&.”
LikeLiked by 1 person
[…] via Shard or be Shredded — Life Less Ordinary […]
<! —
PDRTJS_settings_8450511_comm_2127={“id”:8450511,”unique_id”:”wp-comment-2127″,”title”:”%26%23091%3B%26%238230%3B%26%23093%3B%20via%20Shard%20or%20be%20Shredded%20%20Life%20Less%20Ordinary%20%26%23091%3B%26%238230%3B%26%23093%3B&;&.”
LikeLiked by 1 person
[…] via Shard or be Shredded — Life Less Ordinary […]
<! —
PDRTJS_settings_8450511_comm_2127={“id”:8450511,”unique_id”:”wp-comment-2127″,”title”:”%26%23091%3B%26%238230%3B%26%23093%3B%20via%20Shard%20or%20be%20Shredded%20%20Life%20Less%20Ordinary%20%26%23091%3B%26%238230%3B%26%23093%3B&;&.”
LikeLiked by 1 person
[…] via Shard or be Shredded — Life Less Ordinary […]
<! Love yours, God & Code.
LikeLiked by 1 person